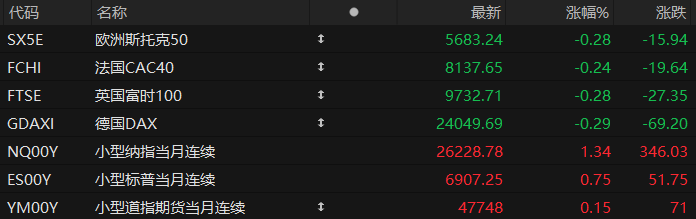
Global storage concept stocks surged today, from US to A-shares. SanDisk (US stock) Western Digital surged 27% Micron Technology surged over 16%, while Hengkun New Materials (A-share listed company) rose 10%. Anji Technology hit the 20% daily limit. Changchuan Technology PuRan Shares Juchen Technology Significantly stronger.
Behind this, Jensen Huang's CES presentation and new products further fueled the already hot storage market.
He stated that storage "remains a completely untapped market." AI-driven storage demands have already exceeded the capacity of existing infrastructure. "The amount of context memory, token memory, and KV cache we're dealing with now is simply too much; older storage systems simply can't meet the demand."
"AI is reshaping the entire computing stack—and now, storage too. AI is no longer a one-off question-and-answer chatbot. " Rather, it is an intelligent collaborator capable of understanding the physical world, performing long-term reasoning, maintaining factual consistency, and utilizing tools to complete real-world tasks, possessing both short-term and long-term memory capabilities.
He then announced Nvidia They will launch a new generation of AI-native storage infrastructure powered by BlueField-4, reconstructing the storage architecture for the next stage of AI, and describing this innovation as "revolutionary".
What is the new storage platform?
NVIDIA 's new storage platform is officially called NVIDIA Inference Context Memory Storage Platform.
According to official sources, the platform expands the available memory capacity of GPUs, providing infrastructure support for context memory and enabling high-speed sharing across nodes.
Architecturally, this platform is actually a high-speed, low-power "context memory" storage layer specifically designed for AI inference , extending the KV cache (KV cache) that could originally only be placed in expensive and limited GPU HBMs to NVMe flash memory and cross-system sharing.
Compared to traditional storage solutions, it can increase the number of tokens that can be processed per second by up to 5 times and achieve up to 5 times energy efficiency optimization.
What are its outstanding features?
This new NVIDIA platform is the first to design AI inference key-value caching as an independent infrastructure layer.
Previously, there were generally three paths to choose from for KV caching: GPU HBM (fast, but expensive and with very small capacity), CPU memory (slightly slower and with limited scale), and SSD/storage (cheap but with uncontrollable latency).
In his CES presentation, Jensen Huang described the innovation as "revolutionary."
He pointed out that this essentially involves adding an extremely fast key-value cache context storage system directly within the rack. The industry is so excited because key-value caching is a pain point for all institutions and enterprises that generate tokens at scale today. "So, the idea of creating a new platform, a new processor to run the entire Dynamo key-value cache context memory management system, and placing it very close to the rest of the rack is completely revolutionary."
AI inference bottleneck shifts to context storage
The term "KV cache" appears frequently in the introduction of the new platform, which is to some extent one of the key reasons that prompted NVIDIA to develop the new platform.
In his latest CES keynote, Jensen Huang emphasized that the bottleneck in AI inference is shifting from computation to context storage . As model size and user adoption increase, AI processing of complex tasks requiring multi-turn dialogues and multi-step inference generates massive amounts of context data. Traditional network storage is too inefficient for short-term context, necessitating a restructuring of AI storage architecture.
This massive amount of contextual data typically exists in the form of key-value caches and is crucial for inference accuracy, user experience, and interaction continuity—the much-anticipated capability of “personalized AI.”
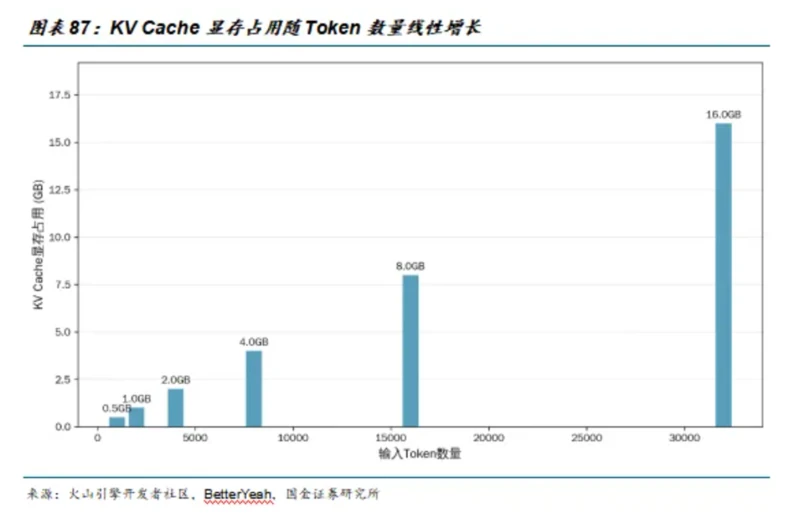
In the "inference era", the memory usage of KV cache increases linearly with the number of tokens, and the optimization effect of KV cache is also positively correlated with the text length.

(Source: Science and Technology Innovation Board Daily)